

Sulphur 424 May-Jun 2026
27 May 2026
AI troubleshooting in sulphuric acid production
MONITORING AND CONTROL
AI troubleshooting in sulphuric acid production
Omar A. Talib of ControlRooms.ai introduces the application of an AI Troubleshooting Agent: a system that analyses real-time plant data to detect anomalies and support proactive troubleshooting between operations, engineering, and reliability teams. Preliminary results from a recent deployment at a major acid producer are presented. The system surfaced early indicators of process drift or sensor degradation, enabling intervention before alarms were triggered or equipment limits were breached.
Sulphuric acid production is one of the most standardised and mature chemical processes in existence. The fundamentals – sulphur combustion, catalytic oxidation to SO3, and absorption in water – has remained consistent for over a century. The industry has improved catalysts, optimised waste heat recovery, minimised emissions, and tightened control schemes. Yet, despite this maturity, unplanned downtime, emission excursions, and slow root-cause analysis remain recurring operational challenges.
Many of these challenges arise not from the chemistry itself, but from how plants are monitored and how information flows between operations, engineering, and reliability groups.
Traditional methods of monitoring with alarms have persisted largely unchanged for half a century. These methods primarily rely on predefined thresholds and static rules, and they continue to leave plant managers and operators vulnerable to disruptions. This article addresses these challenges by introducing the concept of artificial intelligence (AI) troubleshooting.
Evolution of process monitoring in mature industries
Historically, sulphuric acid plants have kept up with the trends in automation. Early implementations of distributed control systems in the 1970s allowed operators to manage their plants from centralised consoles. Over the following decades, additional instrumentation – thermocouples, analysers, flow meters – made the process increasingly data rich.
Increased telemetry yields increased complexity. Typical plants now stream thousands of tags, which are often saved in industrial historians, every few seconds. Despite the abundance of data, most plants still rely on static operating windows and post-event trend reviews for analysis. In other words: reactive troubleshooting. Increased telemetry increased respective alarm thresholds. With this came alarm-flooding. The current status quo can be described as ubiquitous data availability, but limited actionable insight.
An approach that has emerged to deal with nuisance alarms and alarm flooding is “alarm rationalisation.”
Alarm rationalisation
To address the challenge of alarm management facilities often undertake alarm rationalisation initiatives. Alarm rationalisation involves the systematic review and optimisation of alarm systems to ensure that alarms are meaningful, actionable, and not overly burdensome for operators. Alarm rationalisation is a systematic process of reviewing and optimising the alarm settings in a process control system. Its primary objective is to ensure that the alarms provided to the operator are useful, relevant, and actionable.
The rationale behind alarm rationalisation is that an excessive number of alarms, especially those that are not critical, can overwhelm operators, leading to potential oversight of essential alarms or delayed response. This can result in safety issues, process inefficiencies, or production losses.
By far the vast number of these projects are very lengthy – often a year or more. Typical processes take a few months per system involving multiple operations personnel, and sometimes expensive consultants.
In contrast, AI-assisted troubleshooting offers a transformative approach to monitoring complex chemical processes. It is essentially continuous alarm rationalisation by dynamically learning the plant’s changing nature. It hinges on the principle of actively exploring properties and patterns in real-time data streams, rather than relying solely on predefined rules that must be rationalised. AI empowers chemical plants to harness the full potential of their data by identifying subtle anomalies, revealing hidden correlations, and predicting issues before they escalate into costly disruptions.
APC, rate of change modelling, and AI troubleshooting
Advanced process control (APC) and model-based monitoring added predictive capabilities but required extensive configuration, tuning, and maintenance.
Their logic is powerful but rigid. AI-based anomaly detection systems differ fundamentally. Instead of enforcing pre-defined rules, they learn the plant’s multivariate “harmony” of normal behaviour directly from data. They detect deviations not by comparing single variables to limits, but by identifying when “harmony” amongst variables breaks down. This is particularly valuable in sulphuric acid units, where multiple factors (e.g. feed composition, converter temperature gradients, cooling duty, ambient conditions) interact continuously.
Methodology
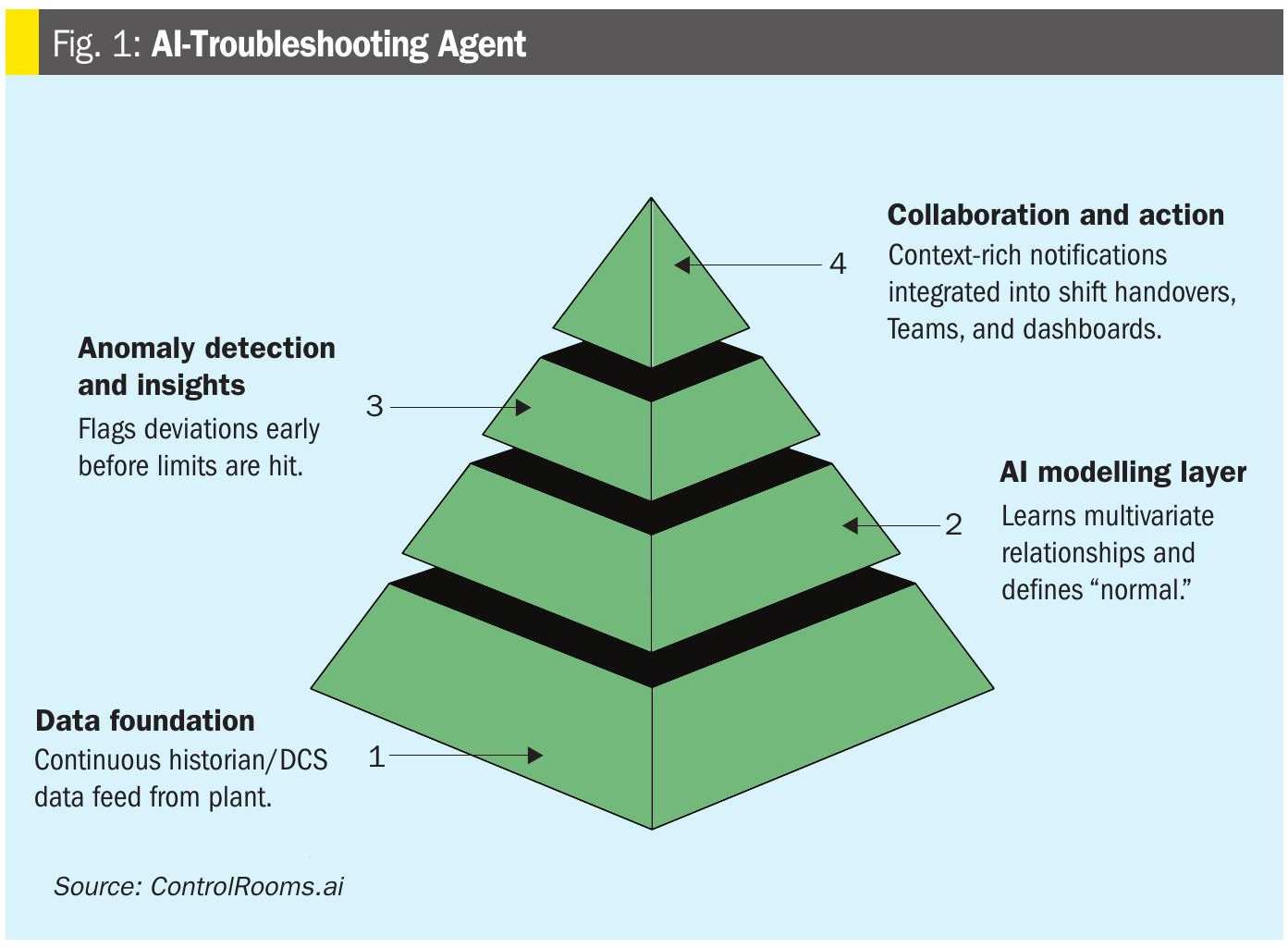
The AI-Troubleshooting Agent (developed by ControlRooms.ai) functions as a layer on top of the plant’s existing data infrastructure (Fig. 1). It connects to the historian or DCS via standard protocols, continuously ingests process data, and establishes a dynamic model of normal operation. No modification to hardware or control logic is required.
Once deployed, the agent performs two primary objectives:
- Reduce mean time to detection (MTTD): multiple families of machine learning models are deployed as appropriate to detect anomalies within on-line plant data.
- Reduce mean time to resolution (MTTR): alerting the relevant parties with the right message at the right time. Leveraging intuitive features to reduce the labour around troubleshooting post-detection of issue.
These techniques collectively allow the system to highlight off-nominal behaviour early – even when all measured variables remain within nominal limits.
MTTD: Multiple well-known modelling types are available natively to the ControlRooms troubleshooting agent (Table 1).
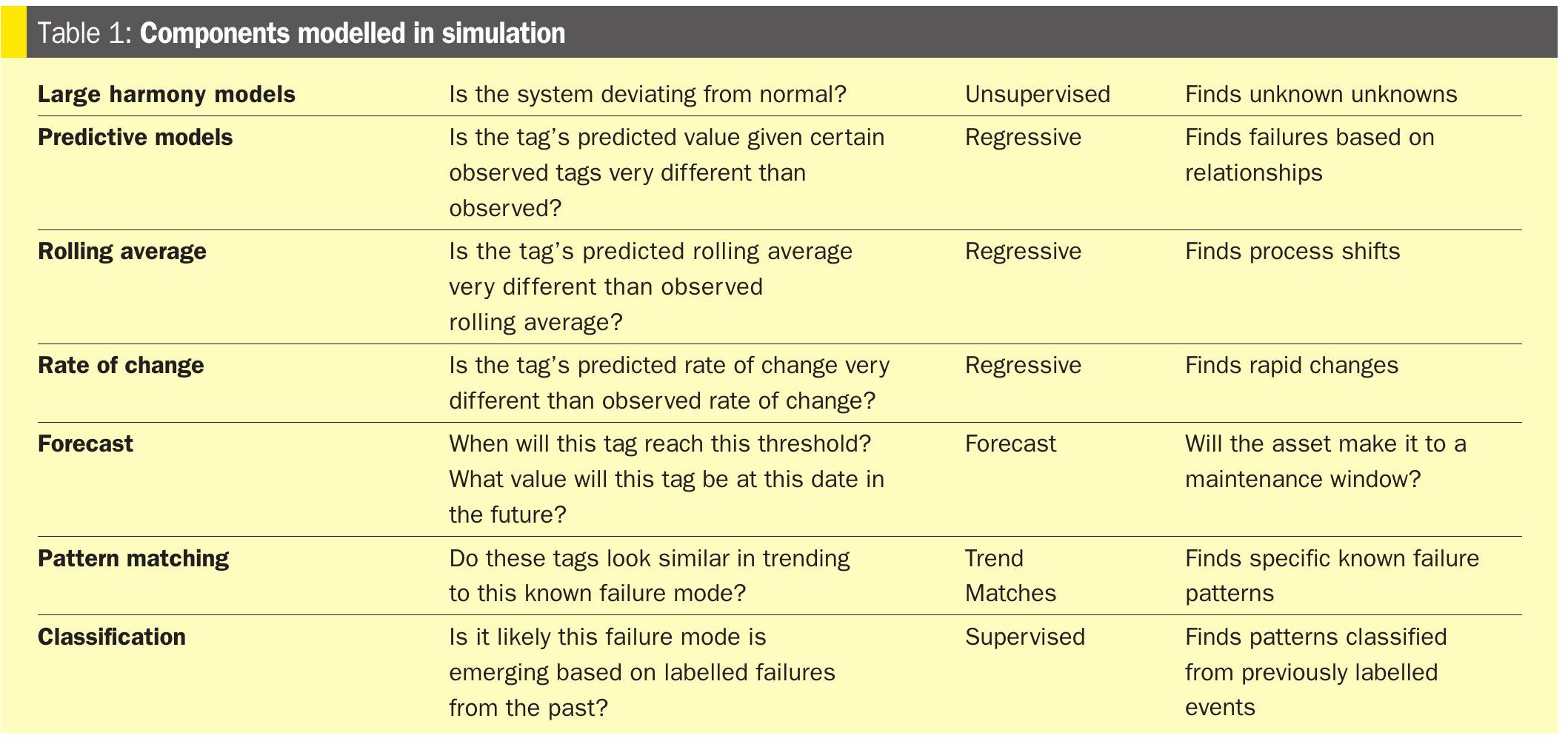
The “large harmony models” however, are unique and allow for “system-monitoring.” Moreover, the large harmony models provide coverage for “unknown unknowns” – issues not predefined.
For example, one simple approach to anomaly detection is to keep statistics on a window of values for a tag and when the values are two standard deviations away from a running average, flag an anomaly. These “univariate” anomaly detection methods are widely used in monitoring applications. While leveraging these dynamic monitoring techniques is better than relying solely on preset rules, these approaches still have many flaws.
Large harmony models
Univariate anomaly detection can be noisy. If one tag is outside of a dynamically computed operating envelope, it does not necessarily mean that there is an actionable anomaly. For the mathematically inclined, these anomaly detection algorithms are called univariate because they only operate on one variable.
In our pursuit of more signal and less noise, we turn to multivariate anomaly detection methods that can determine how groups of variables are behaving with respect to each other. Typically we break up tags according to systems. Sometimes we organise tags by unit, or by area within a unit, or by systems within areas depending on how many tags there are to model. Generally you want between 20-400 tags together in a model for effective anomaly detection.
System-based anomaly detection algorithms are much less noisy because they are modelling the behaviour of multiple variables. In the process industries, tags behave in a certain “harmony” with each other. Even though individual tags might be changing significantly, they are changing together in a harmonious way. In these circumstances univariate methods would be noisy but the multivariate methods can discern that these patterns are ok. Harmony between tags also helps to surface anomalies when things are not changing. Multivariate, system-based methods can catch that some tags should be changing but are steady because other tags are changing.
Benefits of system-based anomalies
Not only are system-based anomalies less noisy, they serve as an early-warning system for operators. Every second matters when troubleshooting in the moment. System-based anomaly detection usually surfaces issues before an alarm storm. Those few minutes can give operators the cushion they need to troubleshoot and take remedial action to stabilise processes before an incident arises.
Even less noise with ensembles
As mentioned earlier, noise is the operators’ nemesis. Even system-based anomaly detection methods can be noisy and alert too frequently. What else beyond using system-based anomaly detection can we do to reduce noise and lower false positives? One very effective method of improving accuracy and reducing noise generally leveraged in the machine learning community is the use of model ensembles.
An ensemble of models is exactly what it sounds like: multiple algorithms that all work together to come to a consensus of whether an anomaly exists. Ensemble based machine learning is a very powerful technique where we apply multiple different algorithms such as tree-based methods, auto-regressive methods, deep learning methods and signal processing methods and combine their results to come up with an optimal answer. This further reduces false positives and improves the actionability of anomalies.
Mean time to resolution (MTTR)
Reducing MTTR requires more than just faster anomaly detection – it requires embedding insights into the daily flow of plant operations. Integration into existing workflows is critical. The AI-Troubleshooting Agent delivered concise, context-rich anomaly summaries that became part of normal communications:
- Shift handovers: brief bulletins listing areas of new or worsening deviation.
- Morning meetings: graphical overviews showing overnight trends across plant sections.
- Event reviews: retrospective anomaly timelines used for investigation and post-trip learning.
- Real-time alerts: real-time AI notifications to respective constituencies. Engineering received more sensitive alerts,operations only the most severe.
To further accelerate resolution, the system supported real-time sharing of views and integration with Microsoft Teams, allowing engineers and operators to jointly examine anomalies during live troubleshooting sessions. Dedicated alert boards within the control room displayed emerging deviations, while engineers used TrendSearch – an AI-based search interface for rapidly visualising related tags and events – to trace anomalies back to their origin.
A key advantage was the ability to perform on-the-fly investigations directly within these shared views. Operators could highlight a drift, launch a TrendSearch in seconds, and invite others into the same visual context via a shared link – eliminating the back-and-forth of screenshots or static reports. This collaborative approach compressed investigative cycles dramatically: what previously took hours of log review and offline coordination could now occur in minutes within a shared workspace.
By embedding these collaborative, context-rich tools into existing routines, the plant shortened feedback loops and reduced MTTR by roughly one-third, transforming investigations from multi-day exercises into same-shift resolutions.
In its current state, the Agent does not recommend actions – it surfaces insights that operational teams interpret within operational context.
Case study: Deployment at a major sulphuric acid facility
Example 1: Blower vibration (Fig. 2)
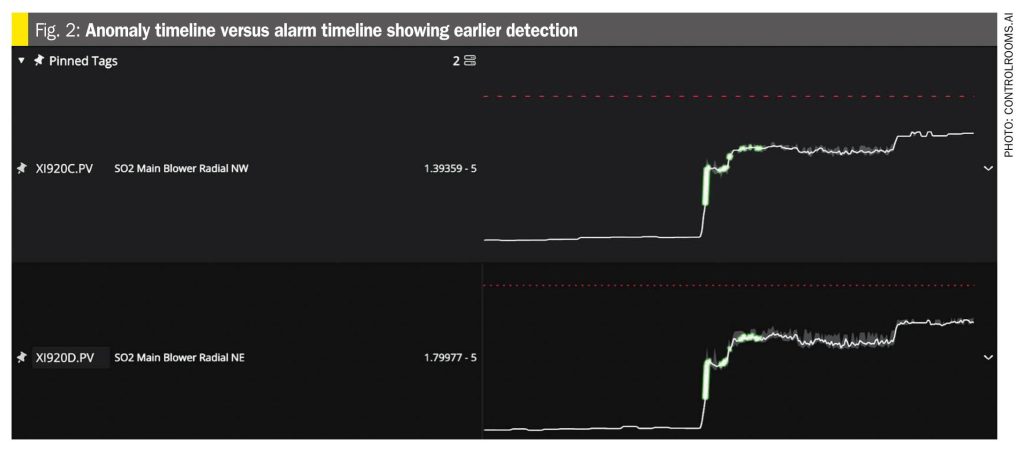
- System flagged a rise in blower radial vibration (green area).
- Increase stayed below the high-alarm limit (red line).
- Detection came earlier than alarms, and was automatically sent to Microsoft Teams channel giving operations time to respond.
- If left unchecked, the vibration could have led to increased equipment damage.
Example 2: Fan current fluctuations (Fig. 3)
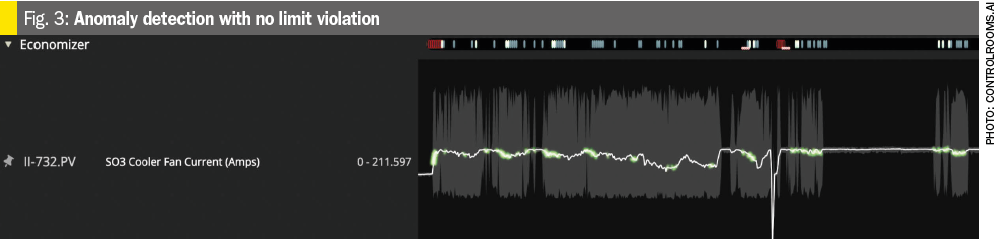
- System flagged abnormal fluctuations in SO3 cooler fan current (green area).
- A previous occurrence of this anomaly went unrecognised, leading to fan failure and a costly repair in addition to production losses.
- When the same pattern appeared again, detection helped operators quickly recognise it as a real issue.
- They corrected the fan dampers on the run, preventing another major failure and avoiding an additional loss.
Example 3: Condenser fouling (Fig. 4)
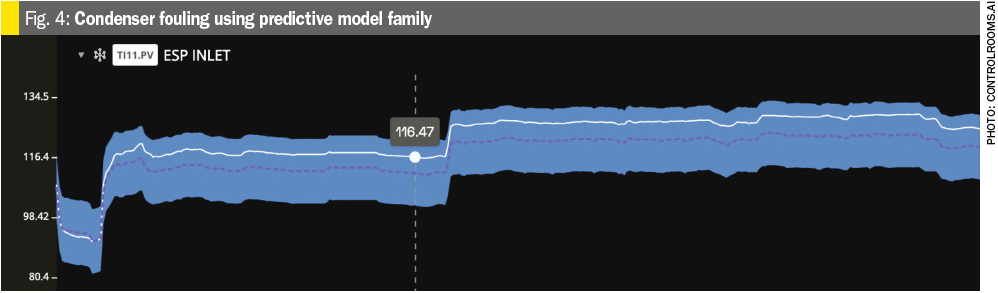
- ML model predicts outlet temperature from cooling water and process conditions.
- Model trained on periods when plant ran optimally.
- Actual outlet temperature (solid white) is running above predicted (dashed purple).
- Points to underperforming condensers, contributing to reduced throughput.
- Provides a benchmark for expected performance and helps pinpoint condenser efficiency as a capacity bottleneck.
Results and impact
Over the first six months of operation, plant teams documented measurable improvements in both detection and resolution times. The Agent prevented multiple day shutdown and level 1 investigation, alerted on a trip before the event, and caught many other events. Most importantly, customer ran at record production over the first year of deployment as a result of AI-based anomaly detection.
Beyond numbers, qualitative benefits were noted: elevated situational awareness, improved collaboration, and greater operator confidence. Cross-discipline learning improved as engineers used AI timelines to accelerate root cause analysis and support operator training.
Implementation learnings
Operator adoption: Success depended on augmenting existing workflows rather than replacing them. The concise, contextual nature of anomaly summaries reduced cognitive load instead of merely adding dashboards. Operators quickly developed trust as early warnings aligned with their intuition or prevented downtime.
Data quality and preprocessing: Data integrity emerged as an important prerequisite. Missing or noisy tags degraded model accuracy. The team implemented automated checks for flat-lined sensors, outliers, and timestamp mismatches.
Change management: AI implementation required cultural alignment. Early engagement with operators, transparent validation of findings, and iterative feedback sessions built confidence in the AI’s ability to detect issues sooner. Weekly joint reviews ensured mutual understanding between plant teams and ControlRooms engineers.
Limitations and future work
While early deployments of the AI-Troubleshooting Agent demonstrated measurable improvements in detection and resolution time, the next frontier lies in explainability and recommendation (Fig. 5). Operators and engineers emphasise that understanding why an anomaly occurred and suggestions on what to do next would be a useful next step.
AI development is now focused on an Explanation Module: a state-of-the-art agentic workflow that fuses multiple sources of knowledge into a coherent reasoning system.
The module draws from:
- General process knowledge of sulphuric acid production, including converter thermodynamics, gas flow behaviour, and chemistry.
- Plant-specific artifacts such as P&IDs, SOPs, shift reports, and maintenance logs.
- The real-time outputs of ControlRooms’ machine learning detection layer, which uniquely highlight where correlations and process behaviours begin to diverge.
At its core, the module builds and continuously updates a “knowledge graph” – a dynamic representation linking process variables, equipment, historical events, and procedural context. This graph enables the agent to trace relationships between anomalies and known operating conditions, identify likely causes, and surface contextual insights drawn from the plant’s own historical record.
When an anomaly is detected, the Explanation Module activates a reasoning workflow that cross-references the Knowledge Graph, historical case data, and relevant documentation. It then generates a natural-language summary of the probable cause, contributing factors, and recommended troubleshooting actions. These outputs are delivered directly to operators and engineers through existing collaboration tools such as Teams or control room specific dashboards, enabling immediate, informed response.
A key aspect of ongoing research is human-feedback reinforcement learning (RLHF). Each time an operator validates, refines, or dismisses an explanation, that feedback becomes training data for improving future reasoning accuracy. Over time, this creates a continuously learning loop – where human expertise and machine learning reinforce each other, refining both the Knowledge Graph and the AI’s explanation logic.
Future iterations aim to close the loop between detection, explanation, and action: an AI troubleshooting system that not only spots anomalies and explains them, but also learns from each resolution to improve plant reliability over time.
Conclusion
The results from this deployment demonstrate that proactive troubleshooting is no longer aspirational – it is operational reality. By leveraging multivariate anomaly detection and seamless integration into daily workflows, the AI-Troubleshooting Agent has already proven its ability to reduce mean time to detect (MTTD) and mean time to resolve (MTTR), transforming troubleshooting from a reactive exercise into a continuous, data-driven process.
These early successes confirm that plants can modernise reliability without redesigning equipment or control logic. The foundation is already in place: real-time detection, collaborative workflows, and intuitive visibility that keeps operations one step ahead.
Looking forward, the next generation of this technology – anchored by the Explanation Module, Knowledge Graph, and reinforcement learning from human feedback – will make these gains even more robust. As AI systems evolve from detecting and contextualising anomalies to explaining and learning from them, proactive troubleshooting will become not just faster, but fundamentally smarter.
References
- Kiss, A. A.; Bildea, C. S.; Grievink, J. (2010). Dynamic Modeling and Process Optimization of an Industrial Sulphuric Acid Plant. Chemical Engineering Journal, 158(2), 241–249. DOI: 10.1016/j. cej.2010.01.023



